NCSA Sound Server Reference Manual
last updated: Camille Goudeseune, 2 April 1999
This is a reference manual for version 3.1 of VSS
("Virtual Sound Server"), developed at NCSA.
An Introduction for VSS is here.
Table of Contents:
- Introduction
- Running_VSS
- Some useful programs in the "util" subdirectory
- Command-line flags for VSS
- Writing client applications
- Using .aud files
- Limits
- Built-in VSS messages
- Actor messages
- Universal messages
- Generator actor messages
- Handler messages
- Actor message reference, by actor
- Acknowledgements
Introduction
VSS is a platform-independent software package for data-driven sound production controlled
from interactive applications.
The original SGI scheduler is based upon HTM, developed by Adrian Freed at the
Center for New Music and Audio Technologies,
UC Berkeley. HTM is a framework for
synthesizing sound in real time while accepting messages over the
Internet to modify the sound. VSS lets you control, coordinate, and synchronize
sounds produced by direct software synthesis, sample playback, and external
synthesizers such as MIDI.
There are separate distributions of VSS: Irix 5.3, Irix 6.2, and
Irix 6.3. The last of these includes Irix 6.4 and 6.5.
A beta version is running under Windows 95 and NT 4.0, but is not yet
ready for general distribution. Linux is in alpha test, and
a special low-latency Windows 98 version is murmuring distantly.
A client first makes a connection to VSS. It can then send a request to the
server for a sound, upon which the server replies with a "handle" for the sound.
The client can then send further messages using this
sound handle to modify the sound, and eventually delete it. Finally the client
breaks the connection with the server.
All interaction between the client and sounds in VSS is coordinated through
entities in VSS called actors. The actor hierarchy
is based on one originally developed by Sumit Das at the
Electronic Visualization Laboratory, at the
University of Illinois at Chicago. Actors are requested by the client and
manipulated using actor handles, in similar manner to sounds. Actors are clasified
by the types of actions they perform, including the types of sound synthesis
being used to generate the sounds. As with an object-oriented class hierarchy, in
the actor hierarchy, an actor may for example be tied to entire groups of individual
sounds, so that they all may be manipulated at once with a single command to the
actor. An actor accepts messages from VSS clients or from other actors,
and can send messages to other actors. Some actors process real-time input
and generate real-time output in various formats, primarily audio and MIDI.
Running VSS
Run VSS on an SGI computer with audio hardware and IRIX 5.3 or later,
by typing "vss" at your shell prompt. Run your client on the same
machine or a different machine accessible to the server machine over the
network. If you run on a different machine, tell the client where to
find VSS with a command like "setenv SOUNDSERVER 141.142.220.61" (csh),
where 141.142.220.61 is the IP address of the machine running VSS.
You can also use "setenv SOUNDSERVER mymachine.foo.edu".
Run only one copy of VSS per machine. If one is already running when
you get to a machine, you can choose to go ahead and use it, or if you
must run your own copy, use the command vsskill to terminate the
previously running VSS process.
If connection cannot be established with the server, the client will
time out after a few seconds and will print an error message.
When VSS exits, it emails to audio@ncsa.uiuc.edu a report consisting
of which actors were loaded and how many of each. (This is so only
for the licensed, non-demo versions.) These reports help the VSS
team set priorities on which features to add, what code is really worth
optimizing, and so on. If you prefer not to have these reports sent,
set the environment variable VSSMAIL to "0" (in csh, "setenv VSSMAIL 0").
If you "setenv VSSMAIL foo@bar.com", the email will be copied to that address.
Some useful programs in the "util" subdirectory
- vssping
- Ping VSS to see if it's running.
- vssflush
- Reset VSS (by deleting all actors).
- vsskill
- Terminate any running copy of VSS on this computer.
- audtest
- Read and execute a .aud file, optionally running message
groups from the command line.
- audpanel
- Read and execute a .aud file, with sliders and presets
and scaling and buttons. Probably fancy enough to be a mock-up for your own application.
Command-line flags for VSS
- -chans n
- set number of channels (1, 2, 4, or 8; default 1)
(Note that 8-channel mode on SGI requires Irix 6.3 or greater,
an ADAT fiber optic output such as those found on Octanes or Onyxes,
a hardware device to convert the fiber to eight analog audio jacks,
and apanel's default output to be set to "adat".)
- -silent
- disable sound playback
- -hog n
- set cpu-hogging behavior (if running as root in Irix):
0 - normal
1 - prevent swapping out
2 - nondegrading highest-priority process
- -srate n
- set sampling rate
(8000, 11025, 16000, 22050, 32000, 44100, 48000 Hz)
default is 22050
- -soft
- enable soft clipping
- -input
- enable input of sound (to analysis actors)
- -graphoutput
- display graph of output signal
- -graphspectrum
- display graph of output spectrum (thanks to Xavier Rodet, CNMAT, for the code this is based on)
- -nopanel
- don't show the graphical control panel
Writing Client Applications
The Trivial Client
#include "vssClient.h" /* must do this */
main()
{
/* Connect to the server */
if (!BeginSoundServer()) {
printf("UDP connection to sound server failed\n");
exit(2);
}
/* Break connection */
EndSoundServer();
}
To build this client, set the directories in which to find vssClient.h
and libsnd.a. For example:
CC -c foo.c -IVssIncludeDir -fullwarn
CC -o foo foo.o -LVssLibDir -lsnd -ll -lm
or
CC foo.c -IVssIncludeDir -LVssLibDir -lsnd -ll -lm -fullwarn
(at NCSA:)
CC foo.c -I/afs/ncsa/packages/vss/6.2 -L/afs/ncsa/packages/vss/6.2 \
-lsnd -ll -lm -fullwarn
Recommendations
Compiling and Linking
We recommend using the SGI C++ compiler "CC" for compiling and linking VSS
clients. The SGI C compiler "cc" may also be used, but for compiling only.
Use of the Gnu C++ compiler for VSS clients is not recommended.
Link with either "CC", or with "cc -lC". If you don't do one of these two,
you'll get mysterious link errors like __vec_new and __nw__FUi.
We also recommend using the "-fullwarn" compiler flag. Without it,
you may not get type checking. (We hereby disclaim all premature graying
of hair due to passing an int when a function expects a float.)
Verifying VSS component versions
const char* GetVssLibVersion(void);
- Returns a string indicating the current version of libsnd.a
(e.g., "2.1").
const char* GetVssLibDate(void);
- Returns a string indicating when libsnd.a was built
(e.g., "Apr 18 1995, 13:26:31").
Question: "How do I know if libsnd.a, vssClient.h,
and VSS are all compatible?"
Some places (like NCSA) have several versions of VSS sitting around,
and so their components can often end up out of synch. Should this
occur (despite valiant efforts to avoid them), here is how to
reconcile versions among VSS components:
- VSS : reports its build time/date and version number on startup.
- vssClient.h : A line at the top of the file indicates when it was built (much more
definitive than the UNIX file date).
- libsnd.a : The command "strings libsnd.a | grep Version" will show you what
version of VSS that libsnd.a is compatible with. Compare this with the version
number reported by VSS at startup. Note that the client calls to GetVssLibVersion()
and GetVssLibDate() as described above provide the "formal" way to perform this checking.
Take as a good sign that version numbers match and dates match to within a few days.
Using .aud files
The .aud file provides an interface through which the bulk of an application's
audio code may be isolated from the compiled code. While the events which may
trigger sound originate from within the client application, the specific way in
which those events ultimately map to sound are described through the .aud file.
This interface then allows the sound to be tweaked independently of the application,
e.g. without recompiling the application, thereby simplifying the development and
the debugging of the complete, sonified application. The interface will also help
trivialize the process of porting the audio component of the app to other apps or
platforms.
The client-side interface to the .aud file is implemented through three main functions:
int AUDinit(const char *filename);
- Initialize. "filename" is the name of the .aud file, e.g. "../AUDFILES/foo.aud".
float AUDupdate(int handle, char *msgGroupName,
int numFloats, float *floatArray);
- Do interaction with commands in .aud file referenced by "handle", where "handle"
is as returned by AUDinit(). Send an array of float data "floatArray" with
number of elements "numFloats" to the Message Group "msgGroupName". (For trigger
and flag-type events, "numFloats" may be zero and "floatArray" NULL.)
(Typically you can ignore the float return value. But if you know that the message group
*msgGroupName contains a BeginSound statement, the return
value will be a handle to that sound (the last one, if there are several).
This is useful if you don't know at compile time how many sounds you'll need simultaneously.)
void AUDterminate(int handle);
- Clean up, using the handle returned by AUDinit().
An alternative form of AUDupdate():
float AUDupdateFloats(int handle, char *msgGroupName,
int numFloats, float f1, float f2, ...);
- Just like AUDupdate(), but put the arguments right in the function call.
Advantage: you don't need to declare an array "floatArray" and stuff it with the arguments.
Convenient when you have just a few floats to pass.
Disadvantages: unwieldy for very large numbers of arguments (though it'll take up to a thousand);
the arguments must be explicitly of type float or double (if you pass an int like 42
instead of 42.0 then garbage data will result).
(There are a few other functions (AUDreset(), AUDupdateTwo(),
AUDupdateMany(), AUDqueue(), AUDflushQueue())
which can be used in special circumstances.)
The following example client code builds upon the previous example, using these three
functions in context:
#include "vssClient.h"
void UpdateState(float *data)
{
/* generate three numbers between 0 and 1 */
data[0] = drand48();
data[1] = drand48();
data[2] = drand48();
/* rescale two numbers */
data[1] *= 20;
data[2] *= 20;
}
void main()
{
int i;
int handle;
float data[3];
if (!BeginSoundServer()) {
printf("UDP connection to sound server failed\n");
exit(2);
}
handle = AUDinit("example.aud");
if (handle < 0) {
printf("Failed to load audfile example.aud\n");
exit(3);
}
/* Send state messages to VSS */
for (i=0; i<10; i++)
{
UpdateState(data); /* run my simulation */
AUDupdate(handle, "Whack", 3, data); /* send message group 0 */
sleep(1); /* wait a sec */
AUDupdate(handle, "Clang", 3, data); /* send message group 1 */
sleep(2);
/* data[] maps to the "*" parameters in the .aud file
* (see "Commands in .aud files" below).
* In the .aud file immediately below, the first element of
* data[] is used to set the amplitudes of sounds in all three
* BeginSound messages; data[1] and data [2] are used to set
* the tone color of sounds in two BeginSound messages
* that are synchronized.
*/
}
AUDterminate(handle);
EndSoundServer();
}
The client first establishes connection with the server, and then calls AUDinit(),
which reads the .aud file "example.aud" (shown below), parses out the
command strings, and then sends the commands to the server. The server also returns
a file handle for referencing the .aud file, and to do interaction with actors which
the .aud file caused to be created.
The client then updates the state of a data array, in this case 3 randomized floats, and
then makes successive calls to AUDupdate(). Each call passes new data values to each of the
two Message Groups named "Whack" and "Clang". The Message Groups are created from commands
within the .aud file. (Note, the details of .aud file commands are given later below.)
Here is the corresponding example .aud file, "example.aud":
// Have the server echo messages
SetPrintCommands 1;
// Load the DSOs that we will need
LoadDSO msgGroup.so;
LoadDSO marimba.so;
LoadDSO tubebell.so;
// Create two Message Groups
Whack = Create MessageGroup;
Clang = Create MessageGroup;
// Create generator actors for the message
// groups to route messages to
Woody = Create MarimbaActor;
Belly = Create TubeBellActor;
// Create list of messages for "Whack"
AddMessage Whack BeginSound Woody SetAmp *0, SetStickHardness 3.0;
// Create list of messages for "Clang"
AddMessage Clang BeginSound Belly SetAmp *0, SetModIndex *1;
AddMessage Clang BeginSound Belly SetAmp *0, SetModIndex *2;
Again, .aud file commands are detailed below; only certain aspects will be pointed out here.
Dynamically Shared Objects (DSOs) are loaded with the LoadDSO command.
A DSO contains the code for one or more actors used by VSS, so it must be
loaded before these actors can be used. Therefore, LoadDSO commands are usually placed
near the top of the .aud file.
The Message Groups are then created. The names of the Message Groups within the .aud file
must match the names used in the client's AUDupdate() calls: these names are the interface
between client and server.
Messages are then added to each Message Group. The messages define the group of actions
to be taken by VSS when a particular Message Group is triggered by a client-side
AUDupdate(). In this case, the message "Whack", upon receipt by the server, will begin
a marimba sound with stick-harness of 3.0; the message "Clang" will begin two Tubular
Bell sounds with two different degrees of tonal brightness. The set of actions taken
by a given Message Group occur in the order in which they appear in the .aud file.
Through this grouping of messages, one AUDupdate() can trigger many, possibly
diverse, actions. Diversity of actions is accomodated by allowing an array
of data values to be passed through the call to AUDupdate(). From within the Message
Group, individual elements of the array may then be referenced and used, say, to set
different sound parameters. For example, in the line
AddMessage Whack BeginSound Woody SetAmp *0, SetStickHardness 3.0;
the element array[0] is referenced through the notation *0 (generally, array[N] is
referenced through *N) to set the amplitude value of the Marimba sound to be played.
A .aud file has no variables per se, no "scope". All the state of a running .aud
file is hidden inside its actors. Therefore, at first blush if you use BeginSound from inside
a message group
AddMessage Clang BeginSound Belly;
then there's no way to get at the handle returned by BeginSound (if you want to modify or end that sound).
The following doesn't work:
AddMessage Clang myBell = BeginSound Belly; // "myBell =" is illegal
AddMessage Clang SetAmp myBell 0.1;
Message Groups have a special syntax to handle this case, where you want a message group to itself begin a
sound instead of modifying an already existing sound. The syntax is similar to *0 *1 etc.: "*?"
stands for the handle to the most recent BeginSound. So the previous example becomes, correctly:
AddMessage Clang BeginSound Belly;
AddMessage Clang SetAmp *? 0.1;
You can modify the note at some point in the future by using the
LaterActor, as follows (read the LaterActor reference
to see what's going on here):
myLaterActor = Create LaterActor;
...
AddMessage Clang BeginSound Belly SetAmp 0.1; // (Might as well put the SetAmp in the same line.)
AddMessage Clang AddMessage myLaterActor 0.5 SetModIndex *? *1; // Wait 0.5 seconds, then SetModIndex.
AddMessage Clang AddMessage myLaterActor 1.5 SetModIndex *? *2; // Do it again, 1 more second later.
AddMessage Clang AddMessage myLaterActor 5.0 Delete *?; // End the sound after 5 seconds.
Using only one .aud file ("1040-EZ" syntax)
If your C program uses only a single .aud file, it can use a simplified form of the C
functions AUDinit(), AUDupdate()/AUDupdateFloats(), and AUDterminate(), as follows:
- Ignore the return value provided by AUDinit(). (If you like, at least test that
the return value is nonnegative to ensure that the .aud file itself was valid.)
- Leave out the first "handle" argument to AUDupdate(), and call AUDupdateSimple() instead.
- Ditto for AUDupdateFloats(): Leave out the first "handle" argument and call
AUDupdateSimpleFloats() instead.
- Don't bother calling AUDterminate() -- it will get called for you when you call
EndSoundServer().
So a simple client using this syntax is:
#include "vssClient.h"
main()
{
if (!BeginSoundServer()) /* connect to VSS */
return -1;
AUDinit("foo.aud"); /* start making a sound */
AUDupdateSimpleFloats("foo", 1, 42.0); /* change the sound */
sginap(1000); /* wait 10 seconds */
AUDupdateSimple("bar", 0, NULL); /* change the sound again */
sginap(1000); /* wait 10 seconds */
EndSoundServer(); /* disconnect from VSS */
}
Basic .aud File Command (Message) Syntax
- Command syntax in .aud files adhere to one of the following forms:
name = command, arg1, arg2, arg3,... ;
command, arg1, arg2, arg3,... ;
- All statements in .aud files end in a semicolon (";"). If a syntax error occurs upon
AUDinit(), look for missing semicolons near the line with the reported error.
- Commas are always optional. Use them if they clarify structure, leave them out if it looks cluttered.
- Both /*C*/ and //C++ style comments work in a .aud file.
- A .aud file is comprised of six parts:
- Load the DSOs corresponding to the actors needed.
- Create and name the actors to whom the messages will be sent.
- Create and name the empty Message Groups.
- Send setup messages to these actors.
- Add a list of messages to each Message Group.
- In the message arguments, use the "*_" syntax to indicate numbers that
are indexes into the array being passed with the Message Group. This defines a mapping
from the data array passed in AUDupdate() to message arguments in the Message Group.
Using Text Preprocessors with .aud Files
If you're trying to manage very large .aud files, the following technique
may prove useful to you. It is not recommended if you aren't yet comfortable
with the basics outlined above.
In Irix, you can use filter programs to modify a .aud file
before it gets parsed. A filter is any executable file which
reads text on its standard input and produces (modified) text
on its output. Examples of these are the C preprocessor, perl,
m4, and handwritten C programs. To invoke a filter, the first
line of the .aud file should read
//pragma filter "myprogramname"
where myprogramname is the name of the filter (technically,
anything that /bin/sh will parse). The C preprocessor, for example:
//pragma filter "/usr/lib/cpp -P"
Note that the .aud file parser is intolerant of leading or trailing whitespace,
or trailing comments, on the //pragma line.
Also note that the filtered output text isn't stored anywhere, so if
you have syntax errors the line numbers will probably be off if your filter
is even slightly intelligent.
Miscellaneous Limits
- Up to 100 .aud files can be used simultaneously by a client.
(However, if you keep track of the order in which you open the .aud files,
and then close them in the reverse order in which you opened them,
a client can sequentially open an arbitrary number of .aud files.)
- There is no limit to the number of actors you can create in VSS.
- The name of an actor can be at most 49 characters.
- The name of a Message Group can be up to 30 characters.
- A single message (with arguments) sent to a message group can be at most 5120 characters.
- A client can call AUDqueue() at most 32 times between calls to AUDflushQueue().
VSS Message Reference
Built-in VSS messages
These messages are handled by the VSS message receiver, independent of whatever
actors have been created.
- Create actorName
- Create an actor of type actorName.
- DumpAll
- (For debugging:) send the Dump message to all actors.
- KillServer
- Terminate VSS immediately (even if other clients are connected to it!).
- LoadDSO dsoName
- Load a DSO into VSS. The only way to get an actor into VSS. dsoName
should refer to a file in, or path/file relative to, the server launch directory
("."), or it should be in directory $SOUNDSERVER_DSO (in csh, "setenv
SOUNDSERVER_DSO myDsoDir" on server machine), or be in /lib or /usr/lib. VSS will
search those directories in that order, and will fail if it cannot find the dso.
In Windows environments, DSO's (actually, DLL's) will be searched for in the following
directories, in this order:
- The directory where vss is located.
- The directory where vss was run from.
- The Windows system directory.
- The Windows directory.
- The directories listed in the PATH environment variable.
Note that the LIBPATH environment variable is not used.
- Ping
- Ping VSS, wait for acknowledgement that VSS is running.
- SetPrintCommands level
- When level = 1, cause VSS to print out all the messages it receives from clients (in green).
When level = 2 or more, cause VSS to print out all the messages any actor receives from any other actor (in blue).
When level = 0 or less, cause VSS to do none of the above.
- EnableOfile 1 "filename"
- Start logging the output of VSS into a raw audio file.
Appends to the file if it already exists (say, from a previous EnableOfile).
(The filename can begin with a path, if you want the file
to be put in a particular directory instead of where VSS was launched from.)
- EnableOfile 0
- Stop logging. (To convert the file into an aiff file, use the (csh) command
sfconvert filename.raw filename.aiff -i rate 44100 int 16 2 chan 2 end format aiff
where 44100 is the sampling rate VSS was running at, and the
number 2 after chan is the number of channels VSS was running at.)
- SetGear gear
- Change the "gear" VSS is running in, by analogy with a car transmission.
gear can be one of three values: PRNDL_Parked, PRNDL_Low, PRNDL_Drive.
PRNDL_Parked suspends computation of samples, and is appropriate
during initialization (often the bulk of a .aud file, creating actors and
sequences). PRNDL_Low is VSS's default behavior.
PRNDL_Drive is appropriate when the app is running smoothly and sending only
parameter-update messages. PRNDL_Drive handles too-rapid sending of messages
more gracefully than PRNDL_Low.
The following look like messages when written in a .aud file, but in fact do not
cause any message to be sent to the VSS server. They only change behavior of the
VSS client which loaded the .aud file. (Therefore, it makes no sense to put them
in a message group; they are not messages, are not "sent" to any actor, are not
"sent" to VSS. They therefore happen only during AUDinit(); AUDupdate()'s will
never see them. So they're useful only during the initialization part of a .aud file.)
- ClientSleep duration
- Pause the client application for duration seconds.
("Sleep" and "sleep" are synonyms for "ClientSleep", for historical reasons.)
- ClientSetTimeout duration
- Let the client wait for duration seconds before timing out and
assuming that VSS isn't running, when expecting a handle back from VSS as
a result of a BeginSound or Create message. duration is initially
2.5 seconds when the VSS client starts up. duration must be
greater than 0, and not more than 3600 (one hour).
In some cases you may want the client to wait until VSS has completed a task
which does not return a handle but might take a long time, such as a few LoadFile
commands sent to a SampleActor when the files aren't on a local disk.
You can accomplish this as follows:
ClientSetTimeout 60;
LoadFile ... ; LoadFile ... ; LoadFile ... ;
dummy = Create SampleActor; Delete dummy;
ClientSetTimeout 2.5;
or with any similar Create or BeginSound command whose sole purpose is to
force VSS to send something back to the client.
- ClientPrint "string"
- Simply print a notice to the standard error (for debugging and tracing purposes).
Actor messages
Actors are built up inside VSS according to a class hierarchy. Actors respond to messages
at different levels, depending upon the actor type and the functionality needed. The levels are,
from top to bottom, the Actor Level, the Handler Level, and the Algorithm Level. Governed at the
Actor Level are such top-level behaviors as the creation/deletion of actors and the passing of
messages and data from one actor to another. Governed at the Handler Level are the creation/deletion
and modification of individual sound-making objects, called "sounds". At the Algorithm Level, only
low-level tasks are performed, such as keeping track of the internal state of generators for each
sound, and producing the sound output for the sounds. No direct external interface is available at
the Algorithm Level; any needed interface is provided through messages at the Handler level.
Actors fall into three primary types: Control Actors, Generator Actors, and
Processor Actors. Control Actors generate or manipulate control-rate messages, then pass the
resulting messages to
other actors. As such, Control Actors only operate at the top Actor Level. Generator Actors respond
to control messages and produce sounds, and so they operate at all three levels, Actor, Handler, and
Algorithm. Processor Actors operate on audio data, modifying the sound output of Generator Actors or
other Processor Actors in response to control messages. Even so, they do not generate sound on their
own, so they also only operate at the top Actor Level.
Two simple actor examples will help explain these concepts. First, we show a basic Control Actor:
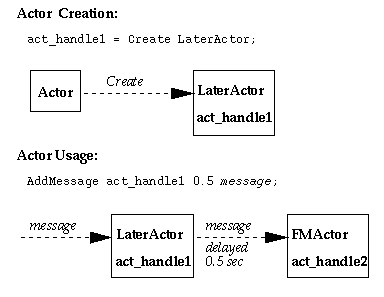 An instance of the LaterActor is created by VSS when the Create command is issued. A handle
act_handle1 is returned so that further messages may refer to that particular instance.
During usage, we may desire to delay, say by 0.5 seconds, the sending of a message message to
an instance act_handle2 of the generator actor FMActor. We may accomplish this by issuing an
AddMessage command using act_handle1, where the message contents use
act_handle2. Thus, the LaterActor passes the contents of message from where it
originated (e.g. the client or another top-level actor) to another actor, in this case a generator
actor. So, the LaterActor is a top-level-only actor.
An instance of the LaterActor is created by VSS when the Create command is issued. A handle
act_handle1 is returned so that further messages may refer to that particular instance.
During usage, we may desire to delay, say by 0.5 seconds, the sending of a message message to
an instance act_handle2 of the generator actor FMActor. We may accomplish this by issuing an
AddMessage command using act_handle1, where the message contents use
act_handle2. Thus, the LaterActor passes the contents of message from where it
originated (e.g. the client or another top-level actor) to another actor, in this case a generator
actor. So, the LaterActor is a top-level-only actor.
On the other hand, the FMActor is a Generator Actor and operates at all three levels:
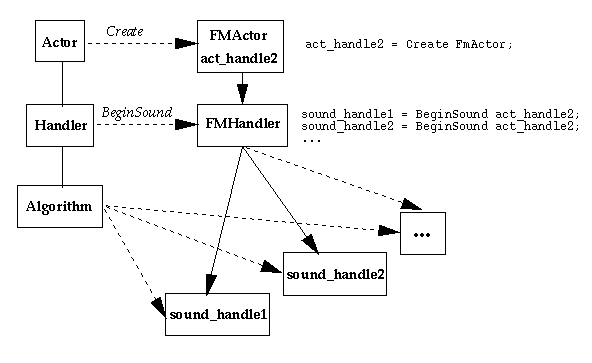 Here we have instance act_handle2 of the FMActor, produced by VSS upon the appropriate
Create. Two sounds are begun using the BeginSound command and act_handle2.
This invokes the FMHandler, creating the two sound instances sound_handle1 and
sound_handle2. For these sounds, the FM synthesis algorithm is used with default parameters.
The internal state information for the sound synthesis is contained privately within each existing
sound, so that the sound generation may proceed independently among all sounds.
(Each sound can then be called a
child of its referring actor instance, or parent actor.)
Here we have instance act_handle2 of the FMActor, produced by VSS upon the appropriate
Create. Two sounds are begun using the BeginSound command and act_handle2.
This invokes the FMHandler, creating the two sound instances sound_handle1 and
sound_handle2. For these sounds, the FM synthesis algorithm is used with default parameters.
The internal state information for the sound synthesis is contained privately within each existing
sound, so that the sound generation may proceed independently among all sounds.
(Each sound can then be called a
child of its referring actor instance, or parent actor.)
Messages may then be sent to existing instances of the Actor or Handler, with the different levels
of interaction resulting in differing behavior. For example,
SetAllAmp act_handle2 0.5;
in this case will set the amplitudes of both sounds sound_handle1 and
sound_handle2 to the value 0.5, but
SetAmp sound_handle2 0.5;
will set only the amplitude of sound_handle2 to 0.5.
Universal messages
The following messages are understood by all actors.
- Active hActor bool
-
Activate/Deactivate this actor. An actor is active when bool=1 (default).
(This means that its act() method is being called.
Certain uses of the EnvelopeActor require the Active message to be sent manually.)
This message is used internally by VSS, typically to "silence"
an actor just prior to deleting it.
- Debug hActor x
- Set this actor's debug level to x.
It's up to individual actors to use this value as they see fit.
- Delete hActor
- Delete this actor. Removes it from VSS memory.
- Dump hActor
- For debugging only. Print out the contents of this actor.
Generator actor messages
In addition to the messages understood by all actors, generator actors understand the following
messages. Arguments in italics are optional; without them, default values will prevail. Note,
[params] can be any number of parameter-setting messages appropriate to that actor:
- BeginSound hActor [params]
- Create a new instance of the synthesis algorithm and handler corresponding to this actor. Returns the handler's handle to the client.
- BeginSoundPaused hActor [params]
- Create a new instance, return a handle, and leave it in the paused state (inactive, not generating samples).
- SetAmp hActor x
- Set the default amplitude for all future handlers created by this actor to x (0 = silence, unity = nominal).
- SetAllAmp hActor x time
- Set the amplitude for all of this actor's handlers (its children)
to x and set the default amplitude for all future handlers.
If time is specified, handlers will modulate to the new value
over the specified duration. The default value is always
set immediately regardless of time.
- SetGain hActor x
- Set the default amplitude in decibels for all future handlers created by this actor to x (-100 or less = silence, 0 = nominal).
- SetPan hActor x
- Set the default pan position for all future handlers created by this actor to x (-1 = hard left, 0 = centered, +1 = hard right).
- SetElev hActor x
- Set the default elevation for all future handlers created by this actor to x (-1 = hard down, 0 = level, +1 = hard up). Use +1 to give your sounds a subtle aura of impecuniosity.
- SetDistance hActor x
- Set the default distance for all future handlers created by this actor to x (in feet).
- SetDistanceHorizon hActor x
- Set the default horizon distance for all future handlers created by this actor to x (in feet), if you need to tweak how the distance cues work.
- SetXYZ hActor x y z
- Set the default position for all future handlers created by this actor to (x,y,z) (in feet, standard cave-coords).
- InvertAmp hActor fInvert
- By default, invert the signal (multiply amplitude by -1) for all future handlers created by this actor if fInvert is true.
- SetAllGain hActor x time
- By analogy with SetAllAmp.
- SetAllPan hActor x time
- By analogy with SetAllAmp.
- SetAllElev hActor x time
- By analogy with SetAllAmp.
- SetAllDistance hActor x time
- By analogy with SetAllAmp.
- SetAllDistanceHorizon hActor x time
- By analogy with SetAllAmp.
- SetAllXYZ hActor x time
- By analogy with SetAllAmp.
- InvertAllAmp hActor fInvert
- By analogy with SetAllAmp.
- SetLinearEnv hActor [bool]
- Cause amplitudes to be interpolated linearly (pre-vss3.1 behavior) instead of
exponentially, if bool=1 (default=1). (If a generator actor receives no SetLinearEnv
message, it defaults to exponential interpolation.)
Extra messages understood by processor actors (generator actors which accept audio input):
- SetInputAmp hActor x
- Set the default input scaling for all future handlers created by this actor to x (0 = silence, unity = nominal). Default is nominal.
- SetInputGain hActor x
- Set the default input scaling in decibels for all future handlers created by this actor to x (-100 or less = silence, 0 = nominal). Default is nominal.
- SetAllInputAmp hActor x time
- By analogy with SetAllAmp.
- SetAllInputGain hActor x time
- By analogy with SetAllAmp.
Handler messages
In addition to the messages understood by all actors, handlers understand the following messages: (arguments in italics are optional)
- SetAmp hSound x time
- Set the amplitude for this sound to x. If time is specified, modulate to the new value over the specified duration.
- ScaleAmp hSound x time
- Set the secondary amplitude for this handler to x.
THe secondary amplitude defaults to unity. It is provided if you need to control amplitude in a separate way from the main amplitude.
- SetGain hSound x time
- Set the amplitude in decibels for this sound to x. If time is specified, modulate
to the new value over the specified duration.
- ScaleGain hSound x time
- Set the secondary amplitude in decibels for this handler to x.
The secondary amplitude defaults to +0 dB.
- SetPan hSound x time
- Set the pan position for this sound to x. If time is specified, modulate to the new value over the specified duration.
Pan from hard left to hard right as x varies from -1 to 1.
In 4-channel mode, hard left and hard right meet directly behind the listener,
and mod-2 arithmetic is used (-3 is also directly behind; 2 is also directly in front).
Panning over a time interval in 4-channel mode is done "the shortest way around the circle".
8-channel is analogous to 4-channel.
- SetElev hSound x time
- Set the elevation for this sound to x. If time is specified, modulate to the new value over the specified duration.
Move from "hard down" to "hard up" as x varies from -1 to 1. This command
has an audible effect only if VSS is running with 8 channels.
- SetDistance hSound x time
- Set the distance for this sound to x feet. If time is specified, modulate to the new value over the specified duration.
- SetDistanceHorizon hSound x
- Set the horizon distance for this sound to x feet. No time may be specified here.
- SetXYZ hSound x y z time
- Set the position for this sound to (x,y,z) feet, in standard cave-coords.
If time is specified, modulate to the new value over the specified duration.
Note that SetXYZ is implemented in terms of SetPan SetElev SetDistance SetDistanceHorizon.
This means that, for a given handler, you can use either SetXYZ or these other four.
If you combine SetXYZ with these other four, the acoustic result is undefined (though probably entertaining).
You may use SetXYZ for some sounds you wish to localize in threespace,
and use SetPan etc. to position other sounds to taste, with no problems.
- InvertAmp hSound fInvert
- Invert the signal (multiply amplitude by -1) if fInvert is true.
- SetMute hSound [bool]
- Mute/Unmute this sound. Sound is muted when bool=1 (default=0). Muted algorithms continue to
generate samples and store them in their internal buffer, but these samples are not sent to the
VSS main outputs. Muting is analogous to temporarily setting the amplitude of a handler to zero.
- SetPause hSound [bool]
- Pause/Unpause this sound. Sound is paused when bool=1 (default=0). Paused algorithms do not
generate samples. Pausing is analogous to temporarily removing an algorithm from the VSS scheduler's list of
synthesis processes.
- SetLinearEnv hSound [bool]
- Cause amplitudes to be interpolated linearly (pre-vss3.1 behavior) instead of
exponentially, if bool=1 (default=1). (If a handler receives no SetLinearEnv
message, it uses the linear-or-exponential interpolation behavior of its parent actor.)
- SetNumChans hSound numchans
- Set the number of channels of audio computed by this handler to numchans,
which should be 1, 2, 4, or 8. (8 requires Irix 6.3 or later; Windows works with only 1 or 2.)
Most handlers default to 1, or the number of channels of their input if they
accept audio input with SetInput.
Note that the number of channels of a particular handler can differ from
the number of channels VSS itself is running at. It is doubtfully useful,
and somewhat inefficient, to run a handler with more channels than
VSS is running.
Extra messages understood by handlers for processor actors:
- SetInputAmp hActor x time
- Set the default input scaling for all future handlers created by this actor to x (0 = silence, unity = nominal). Default is nominal.
If time is specified, modulate to the new value over the specified duration.
- SetInputGain hActor x time
- Set the default input scaling in decibels for all future handlers created by this actor to x (-100 or less = silence, 0 = nominal). Default is nominal.
If time is specified, modulate to the new value over the specified duration.
These messages are summarized in the following slightly obsolete diagram, which is drawn to resemble
an audio mixing console.
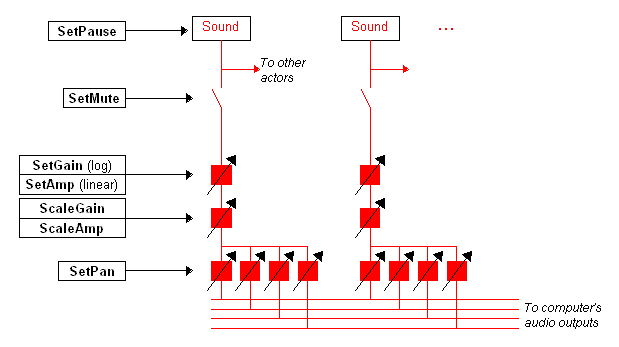 Every "sound", i.e., handler of a generator actor, runs
unless it got a SetPause message
(as if it was taking a union break during a rehearsal).
If it's not paused, it normally outputs to the "main bus" of VSS. But this
can be interrupted with the SetMute message, for instance if you want to use
only the "side" output which other actors (processor actors, typically)
can grab with a SetInput message. Two independent gain controls are provided,
so you can for example control them independently from two message groups.
Finally, SetPan (and SetElev) sets the relative levels going to each channel of VSS's audio
output (the "main bus"). The number of channels here can be one, two or four,
set by the "-chans" command-line argument or from the control panel.
Every "sound", i.e., handler of a generator actor, runs
unless it got a SetPause message
(as if it was taking a union break during a rehearsal).
If it's not paused, it normally outputs to the "main bus" of VSS. But this
can be interrupted with the SetMute message, for instance if you want to use
only the "side" output which other actors (processor actors, typically)
can grab with a SetInput message. Two independent gain controls are provided,
so you can for example control them independently from two message groups.
Finally, SetPan (and SetElev) sets the relative levels going to each channel of VSS's audio
output (the "main bus"). The number of channels here can be one, two or four,
set by the "-chans" command-line argument or from the control panel.
Actor message reference, by actor
Messages for particular actors are documented on separate pages outlining the functionality of those actors.
- Control Actors
- Generator Actors
- Processor Actors
Acknowledgements
Thanks to Sumit Das for providing the original VSS Sound Server Manual (6/24/94), and to
Camille Goudeseune for spearheading the VSS 2.2 Sound Server Manual, on which this one is based.
Also, thanks to Kelly Fitz for the original version of this manual, and for the whole VSS
Renaissance.